こんにちわ。 Baseconnectバックエンドエンジニアの河野です。
今回は弊社営業支援ツール「Musubu」で提供している機能の一つに活動履歴という、営業案件に対してユーザーが行なったアプローチをログとして残すものがありますが、その活動履歴について新しいDBに対して非同期でレプリケーションを行うパイプラインの整備&技術検証などを行なったのでシェアできればと思っております。
プロジェクト背景
この活動履歴という概念がサービスの要件として登場したのは創業初期の段階で、詳しい事情は知らないのですが現状DynamoDBをマスターDBとして利用しています。
NoSQLでスキーマレスなデータ構造に強く、設定したプライマリ&セカンダリのインデックスで高速検索にはもってこいの優れたマネージドDBではあるものの、欠点として1度の検索に使える軸が多くても2つまでという点があります。
今後の活動履歴を活用した営業案件の検索などのサービス構想上、3つ以上の検索軸の発生 & Elasticsearchに保存されている営業案件と組み合わせた検索の発生という点を鑑みて、
活動履歴のマスターDBとしてはDynamoDBを残したまま検索用のDBとしてElasticsearchにレプリケートし、 活動履歴を用いて営業案件の検索を行なったり案件を横断した活動履歴の集計などを行えるような土台を整えたという流れになります。
進め方
設計
パイプライン設計
要件
- 非同期遅延を最小化
データパイプライン使用によって発生する非同期遅延がどの程度か実装しながら検証し、企画と相談。 - DynamoDBのaction logテーブルのパーティションキーごとにストリーミング処理の順序を担保
任意の活動履歴への更新のレプリケートはorder criticalなので。 - 活動履歴変更イベントをサブスクライブするコンシューマーが増える可能性を考慮
前提
dynamoDB streamのシャード(パーティション)ごとの直列処理

争点
①dynamodbのキャプチャリングデータをどこに流すか
- dynamoDB stream
- kinesis data stream

判断材料
■ s3, es, redshiftへのコードレスなデータレプリケーションを使用する機会は今後登場するか?(kinesis firehose)
結論: 今のところ必要ないので、必要になり次第ダウンストリームにkinesisを配置。リアルタイム分析の機会が今後登場するか?(kinesis analytics)
結論: 今のところ必要ないので、必要になり次第ダウンストリームにkinesisを配置
■ シャード数を柔軟にコントロールする意味があるか?
- 現在はシャードごとにParallizationFactorを調整することで、シャードごとのlambda並列度を1~10まで設定可能
- DynamoDBは10GBごとに、もしくはWCUが1000, RCUが3000を超えるたびにシャードが1つ増加する
- kinesisは自由にシャード数の調整が可能
結論: ParallizationFactorの調整である程度のスケールは可能なので、一旦シャード数の管理がマネージドで実装しやすいdynamoDB streamを採用し、 負荷テストなどの検証の結果シャード数が少なすぎて並列度が足りないということであれば、kinesisへピボットする
■ ストリームへのデータ保持期間を24日以上にする必要があるか?
結論: 今のところ必要はないので、必要に応じてダウンストリームのkinesisに流し込む
■ data producerが増える可能性があるか?
- kinesisはあらゆるソースからのストリームデータの収集が可能
- DynamoDB StreamsはDynamoDB Tableのみ
結論: 活動履歴以外のモデルについては、DynamoDBではなくNeo4jというグラフDBに保存されているため、それらモデルについても非同期レプリケーション機能を採用しようとした場合、kinesis data stream1択になる。ただその場合、モデルごとに独立したストリームをこしらえることが予想されるので、kinesis data streamを複数のproducerで使いまわすことは考えにくいため、活動履歴用のストリームに対するdata producerを増やせるという利点にあまり魅力は感じない
■ コンシューマーが増加するかどうか
- kinesis fenhanced fanoutなら最大20のコンシューマーにほぼリアルタイムのストリームデータを提供可能
- dynamoDB streamの場合、最大コンシューマーは2つなので、間にsqsやkinesisを介したファンアウトパターン必須。
結論: 必要になればダウンストリームにkinesisを追加すれば良い
- 重複コードへの対応、orderの順序担保をlambdaレベルで実装することを許容するか
- kinesisの場合、信頼性(レコードが重複したり)、順序性(orderが担保されない場合)についてアプリケーションレベルで担保する必要がある。
所感
上記の各判断材料を鑑みて実装コスト高いkinesis data streamを採用する理由は乏しいので、一旦DynamoDB Streamsを採用して、後にkinesisの需要が高まればダウンストリームとしてkinesisに流し込めば良い。
またDynamoDB Streamsで実装した際に、シャードのコントロールができない等の原因でストリーム詰まりが発生するようなら、データのESへのレプリケーションビジネスロジックはそのままで、streamとの繋ぎ込み部分だけkinesis用に交換すれば良い。
②ストリームのコンシューマーはlambdaで良いか
- 同時実行数についての懸念
- 将来的に活動履歴以外のモデルのレプリケーションも実装する場合の統一性
所感: 活動履歴以外のデータのレプリケーション方法が上記の通りなら、コードの再利用性やアーキテクチャの統一性を重視して、lambdaではなく、DynamoDB Streams Kinesis Adapter を使用したKCLと同じインターフェースでのDynamoDB Streamsへの繋ぎ込みをec2上に展開するのはあり。
とはいえ、service quotaに引き上げという最終手段もあるので、実際に占拠される同時実行数の温度感などの検証も含めて、管理コストの低いlambdaでサクッと実装するのが本プロジェクトの温度感としてもちょうど良いかなと考える。
考慮事項
lambdaについての考慮事項 - シャードあたりの並列同時実行数(parallelization factor)
結論: 監視して、もしストリーム詰まりが発生するようなら、随時調整。 - pollingでのバッチサイズ - 2以上にしてしまうと、同じパーティションに対する変更が2回以上起こらないとesに同期されない。
結論: リアルタイム性が求められるため、バッチサイズは1 - polling間隔 - dynamoDB streamは1秒に4回 - kinesis streamは1秒に1回(ベースレート)
結論: batch windowでポーリング間隔を引き伸ばすことは可能だが、リアルタイム性の担保のため、いじる必要性はない - retry処理 - ストリームをイベントソースにするlambdaは同期的にシリアルに動くので、エラーが発生した場合、成功するか24時間経ってデータがストリームから削除するまで後続処理をブロックする
結論: リアルタイム性を担保するためにretry処理の最大試行回数を3,4回に設定し、上限を超えた場合はDLQへ。 - 同時実行数(ボトルネック) - スロットリングエラーが出た際は成功するまでretryをしてDLQに退避できないので、リアルタイム性を維持するために速やかなスケールが必要
結論: 現状の活動履歴の更新回数やシャード数(ほぼ1では?)では特にスロットルされる懸念はないので特に対策する必要はない。 様子を見てスロットル回数などのモニタリングを行い、適宜同時実行数の予約やservice quotaの引き上げなどを行う
遅延速度の検証
今回の設計でレプリケーションにどれくらいの遅延が生じるかも検証しなければなりません。
まずは現在のリクエストレートを算出し、それに準ずる負荷をかけ問題がないかを確認し、そのあとは逆の方向でどれくらいの負荷までなら耐えれるかを計算し、将来的なパイプラインのスケール性に目処を立てます。
リクエストレート算出フロー
現状のDynamoDB の本番テーブルのピーク時の消費キャパシティユニットから本番でのリクエストレートを算出します。
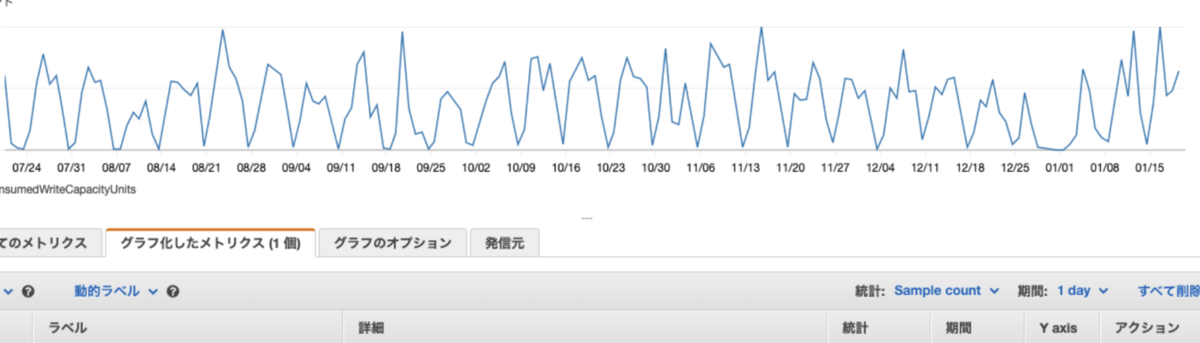
上記フローより、現状の本番環境では活動履歴の書き込み操作はピーク時のレートが分かりました。
負荷テストの実施方法
負荷テストツールを使う方法もありましたが、rakeタスクで自作し、達成したいリクエストレートが出るようにrubyの並列度を調整します。
1回目

2回目
2回目以降は、どのレートであればパイプラインがレイテンシ的に耐えられなくなるかの視点で行っています。
観測されたリクエストレート: 63回 / 1秒
並列度を上げたためかなり負荷がかかっており10秒以上同期が遅延してるのが読み取れますね。

3回目
2回目と同じリクエストレートで、lambdaの並列数を上げるとどうなるでしょうか。 DynamoDB Streamのためシャード数の調整はできないため、シャード数に応じたlambdaのスケーリングはできませんが、1シャードあたりのlambdaの並列度はParallelization Factorというlambdaのパラメータを調整することで~10並列までコントロール可能です。
この並列度を3にした結果、63回/1秒のレートでも遅延が大幅に減っており、アプリケーション要件を達成しうるものです。

4回目
ではこのParallelization Factorを限界の10に設定してもなお、遅延が抑えられないレートとはどの程度でしょうか。
下図の通り、200回/sのレートで送ってみた場合、lambdaの並列度を10にしても一部で5秒ほどの遅延が生じていることからこの辺りの負荷になってくると、現状のパイプライン設計がボトルネックを帯び始めることが分かります。

結論
現状の本番環境のリクエストレートを遥かに高くした負荷(20回/s or 60回/s)で検証したが、 20回/sの場合は、lambdaの並列度が1のままでも平均1秒以内にレプリケーションが完了していることが分かりますね。(実際は検索で使えるようになるまで、Elasticsearchのrefreshまでの時間がプラスで加算されます)
また、どの程度の負荷であれば現状のパイプラインでは耐えきれなくなるか検証したところ、 60回/sのレートで遅延が10秒以上発生するようになっていました。
しかしこれもlambdaの並列度を3にすることで、平均1秒強にレイテンシが抑えられることから、今後爆発的に活動履歴の書き込み操作のレートが上昇しても、検索できるまでの遅延を1, 2秒程度に抑えることが可能ではあるでしょう。
ただ、リクエストレートが200回/s程度に近づいた場合、DynamoDBの1シャードあたりのlambdaの並列度の上限である、10にしたとしても、一部のデータについては5秒ほど遅延が生じるため、これ以上のリクエストレートで遅延を大きくしたくない場合は、別の方法を考えなければなりません。
DynamoDBのシャードは、1つあたり以下の上限を持っています。 - ストレージが10GB - RCUが3000 - WCUが1000
ですので半ば無理やりこれらの値を調整し、シャード数に引き上げによる並列度のさらなる上昇も実現可能ではありますが、費用もバカにならずコストパフォーマンスは最悪ですので、シャードを自由に設定できてlambdaの並列度をほとんど制約なく上昇させられるKinesis Data Streamへの移行が必要になってきます。
とはいえ、ビジネスサイドと相談したところ、秒間200回のレートに達するのはまだ先のお話...
とりあえず、DynamoDBに対するレートのメトリクスを監視し、十分なバッファを持ってstream移行ができるよう体制を構築し、直近では今回の設計で問題なしということになりました。
感想
まず、今回重要だったのが”どれだけリアルタイムにレプリケーションを行えるかどうか”という点でした。 ユーザーの活動履歴をすぐに検索できる事が求められていたので、1分を超えるような遅延は実用的ではありません。
そういった中で、レプリケーションの時間を測定するためにログを仕込む必要が生まれ、そのログをキャッチするためにCloudwatchで独自のクエリを組まなければならないのですが、そこにはかなり苦労しました。やはり言語は無闇に独自仕様が生まれるのではなく、統一的な仕様があったほうが良いですね(笑)
また、Musubu本番で起きうるリクエスト例や、実際に負荷のかかるリクエストレートを想定し、データの生成をうまくシミュレーションして負荷をかけつつ、それに対して遅延問題のクリアを試みます。並列処理をしないと遅延が大きくなってしまうことが分かっていたので、Lambda関数などの並列度を上げながら色々試行錯誤し、
最終的にデータの整合性・堅牢性・冪等性といった考慮すべきところをクリアしたうえで、遅延3秒以内という実用的な数値に抑えることができてかなり嬉しかったです。実際にレプリケーションを行うという試みは技術的経験としては初めてのものだったので、今回の結果はかなり自信に繋がりました。
自分にとって、「大規模データ処理の世界」とは、まるで断崖絶壁のような答えの見えない世界だったのですが、今回の経験によって断崖絶壁の中に階段が生まれ、答えに辿り着く道筋が示されたような気分になりました。まだまだ奥が深いので、これから階段を少しずつ登っていきたいなどと考えています!